
Grandes modelos de IA contribuem para a operação e manutenção inteligentes dos vagões aéreos: perguntas e respostas da base de conhecimento RAG e diagnóstico assistido de avarias
天车出故障最怕什么?不是故障本身,是找不到人修。厂里熟悉老设备的那位老师傅退休了,新来的学徒翻着三百多页的说明书找不到对应页码,一个变频器报警能在现场折腾一上午。这是我们做维保改造时最常听到的抱怨。
AI大模型(大型语言模型,LLM)这两年发展极快,结合天车数字孪生系统中的数据可以为故障诊断提供更丰富的上下文,从通用聊天到垂直行业应用,技术路径已经走通了。天车运维正好是适合大模型落地的场景——知识体系相对封闭(就那几本说明书和维修手册)、故障模式有规律可循(常见的报警代码不超过100类)、决策风险可控(AI给建议,人做判断)。
本文讲的是从部署到落地的完整工程方案:本地跑Ollama接上RAG知识库,天车故障诊断一搜就有答案。硬件投入3~8万,一台工控机能带20~30个维修终端,知识库建好之后永不过期。
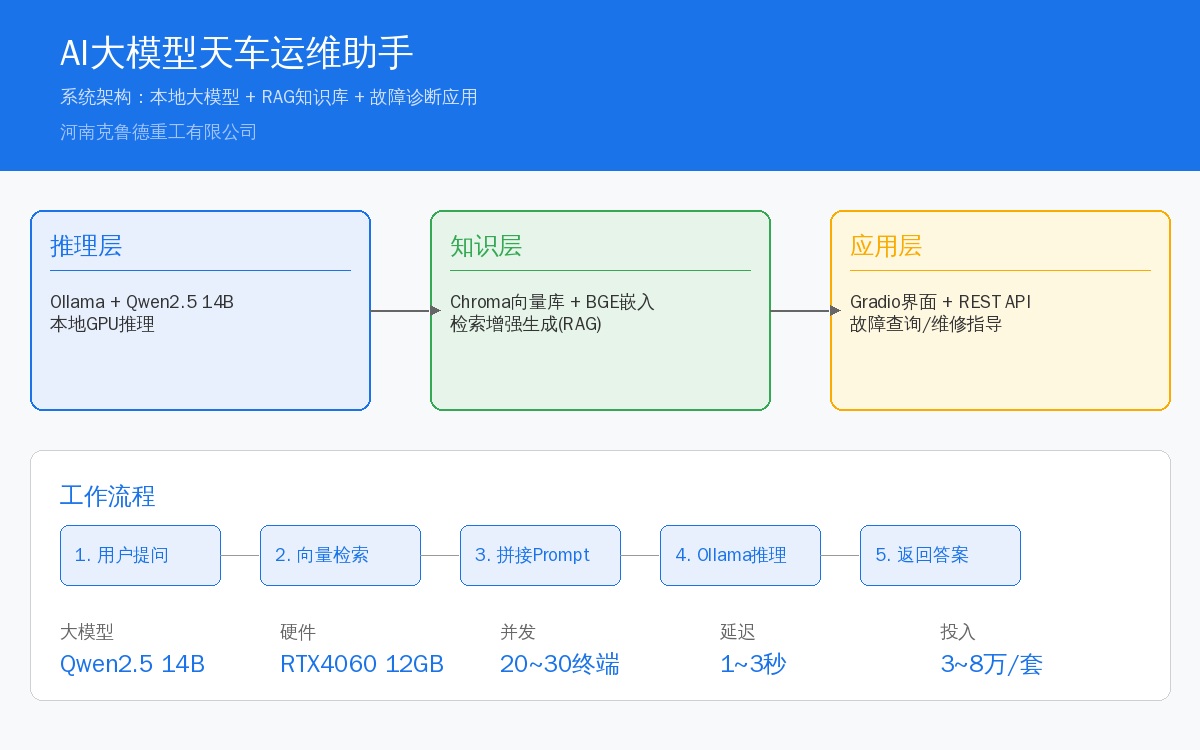
一、系统架构总览
AI运维助手系统采用三层架构,每一层各管各的事,层与层之间通过标准API通信:
| 层级 | 功能 | 核心组件 | 数据流向 |
|---|---|---|---|
| 推理层 | 运行大模型,处理问答请求 | Ollama + Qwen2.5 14B | 用户→Ollama API |
| 知识层 | 语义检索+上下文增强 | 嵌入模型 + Chroma向量库 | 检索→拼接Prompt |
| 应用层 | 前端界面+系统集成 | Gradio/Ollama WebUI + REST API | 用户→推理→返回 |
二、技术实现细节
整个系统的搭建分四个步骤,每一步都有明确的工具选型和配置参数。
2.1 大模型部署:Ollama + Qwen2.5
Ollama是目前最成熟的本地大模型运行框架,支持Linux和Windows,一条命令装好模型就能调用API。推荐用阿里Qwen2.5 14B(140亿参数)——中文理解能力强、对硬件要求适中,量化后的4-bit版本仅需8GB显存就能流畅运行。
部署命令:
# 安装Ollama(支持GPU自动探测)
curl -fsSL https://ollama.com/install.sh | sh
# 拉取Qwen2.5 14B(约8.5GB)
ollama pull qwen2.5:14b
# 启动服务(默认127.0.0.1:11434)
ollama serve验证服务正常:
curl http://localhost:11434/api/generate -d '{"model": "qwen2.5:14b","prompt": "天车变频器报OC过流故障可能原因?列出五条","stream": false}'2.2 RAG知识库构建
纯靠大模型自己的知识是不够的——Qwen2.5虽然知道天车的大概概念,但不知道你家那台特定型号的PLC怎么复位、不知道去年换过哪一批备件。RAG(检索增强生成)就是解决这个问题的:把说明书、维修记录、图纸扔进向量数据库,每次提问时先检索相关文档,把检索结果拼到Prompt里,再让大模型回答。
知识库的构建流程:
| 步骤 | 操作 | 工具/方法 | 耗时 |
|---|---|---|---|
| 1. 文档整理 | 收集说明+电路图+维修手册+故障记录 | PDF/Word转Markdown | 1~3天 |
| 2. 文档切分 | 按章节切小块(每块500~1000字) | LangChain文本切分器 | 10分钟 |
| 3. 向量嵌入 | 文本块转向量(768维) | BGE-small-zh-v1.5 | 按文档量 |
| 4. 向量入库 | 存储到向量数据库建立索引 | ChromaDB / FAISS | 5分钟 |
| 5. 检索测试 | 测试典型问题的检索命中率 | 脚本自动评估 | 半天 |
向量数据库选型推荐ChromaDB——纯Python实现、无需单独部署、支持内存模式,适合工控机上跑。嵌入模型推荐BAAI的BGE-small-zh-v1.5(384维,仅150MB,在CPU上单次推理约50ms),中文语义检索效果好、对硬件要求低。
2.3 检索增强生成流程
一次完整的问答流程如下:
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
import requests
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5")
db = Chroma(persist_directory="./crane_kb",
embedding_function=embeddings)
question = "变频器报OU过压故障怎么处理?"
docs = db.similarity_search(question, k=4)
context = "\n\n".join([d.page_content for d in docs])
prompt = f"""基于以下天车维修手册回答用户问题。
如果手册中没有,说"手册未找到对应内容"。
手册内容:
{context}
问题:{question}"""
resp = requests.post(
"http://localhost:11434/api/generate",
json={"model": "qwen2.5:14b",
"prompt": prompt, "stream": False})
print(resp.json()["response"])这个流程的核心是Prompt拼装。RAG的效果好不好,关键不在大模型(Qwen2.5足够),而在于检索出来的文档是不是真正相关。建议测试时对每个典型问题手动打分(命中率、答案准确率),低于80%就要调整切分策略或嵌入模型。
推荐评估脚本:
def evaluate_rag(test_qs, db, llm_url):
results = []
for q, expected in test_qs:
docs = db.similarity_search(q, k=4)
hit = any(expected in d.page_content for d in docs)
results.append({"q": q, "hit": hit})
rate = sum(1 for r in results if r["hit"]) / len(results)
print(f"Retrieval hit rate: {rate:.1%}")
return results三、典型应用场景
3.1 故障辅助诊断(最高频场景)
维修工在手机或平板上输入故障现象,AI给出可能原因和处理步骤。以变频器OC过流故障为例:
| 输入现象 | AI返回内容 | 处理耗时对比 |
|---|---|---|
| 变频器报OC过流,每次加速时跳闸 | 可能原因:1.加速时间过短 2.电机绝缘老化 3.变频器输出侧短路 建议:先测电机绝缘电阻 | 人工查手册: 15~30min AI辅助: 1~2min |
| 大车运行异响,伴随轻微抖动 | 可能原因:1.轨道接头不平 2.车轮轮缘磨损 3.驱动联轴器间隙 建议:先检查轨道接头高差 | 人工查手册: 20~40min AI辅助: 1~2min |
| 起升电机温度高,超过85°C | 可能原因:1.负载率过高 2.制动器未完全松开 3.电机冷却风扇故障 建议:先测制动器间隙 | 人工查手册: 10~25min AI辅助: 1~2min |
3.2 维修指导(带分步操作)
AI不仅告诉你怎么回事,还告诉你先拧哪颗螺丝。知识库中每类维修操作都以标准化步骤记录:
用户问:怎么更换天车制动器摩擦片?
AI答:以下是更换步骤——
1. 断电挂牌,确认制动器处于释放状态
2. 拆除防尘罩固定螺栓(M8 x 4)
3. 用专用工具压缩制动弹簧
4. 拔出摩擦片定位销
5. 取出旧摩擦片(注意正反位置)
6. 安装新摩擦片(确认厚度一致)
7. 释放弹簧,恢复防尘罩
8. 调整制动间隙(标准值0.5~1.0mm)
9. 通电试车:点动起升3次,确认无异响3.3 历史故障分析与趋势
AI能统计过去一年的故障记录,找出高频问题。对接天车远程监控平台的数据接口后,维修工查询某个故障时,AI自动补充”这台天车过去3个月同类故障出现过4次,建议通知厂家做系统性检查”。

四、关键技术选型表
| 组件 | Solução recomendada | 替代方案 | 硬件要求 | 选型依据 |
|---|---|---|---|---|
| 大模型框架 | Ollama | vLLM / llama.cpp | CPU/GPU均可 | 部署简单中文友好 |
| 大模型 | Qwen2.5 14B | Qwen2.5 7B / DeepSeek | 8GB+ VRAM | 中文推理能力强 |
| 嵌入模型 | BGE-small-zh-v1.5 | m3e-base / text2vec | 无需GPU | 384维轻量模型 |
| 向量数据库 | ChromaDB | FAISS / Milvus | 4GB+ RAM | 纯Python免部署 |
| 前端界面 | Gradio | Open WebUI | 低 | 快速搭建支持手机 |
| 推理硬件 | RTX 4060 12GB | RTX 3060 / MPS | — | 性价比最优 |
五、工程实施要点
1. 知识库质量决定一切。 大模型本身只是引擎,真正干活的是知识库。启动之前花至少一周时间整理天车的全套资料:操作手册、电气原理图、PLC程序注释、历史故障单。如果历史维修记录没有电子版,安排专人把纸质维修单录入为Markdown。知识库的质量直接决定了AI回答的准确率,投多少时间都不亏。
2. Prompt模板要反复调。 同样一个问题,不加系统提示词的回答和加了精心设计的提示词,质量差两个档次。推荐格式:天车AI助手的System Prompt包含角色定义(”你是一位有15年经验的天车维修工程师”)+ 回答规范(”先给出最可能的原因,再列检查步骤,每步标注耗时”)+ 免责声明(”以上为AI辅助建议,最终维修操作请由持证人员确认”)。
3. 离线部署没有想象的那么贵。 很多人以为大模型必须上A100显卡,但其实Qwen2.5 7B量化后在RTX 3060上就能流畅运行,一台工控机带20~30个终端的并发完全够用。如果厂区机密性要求不高,也可以考虑云端方案——Qwen via阿里云API或DeepSeek API,按token计费。不过工业场景我还是推荐本地部署,数据不出网,延迟稳定在1~3秒以内。
4. 不要期待AI替代人。 大模型在天车运维中的定位是”辅助工具”——缩短查资料时间、提供检修思路、减少经验依赖。真正动手操作、最终判断决策,还得维修师傅自己来。把这个定位跟厂里说清楚,大家接受度就高了。
5. 从简单场景切入,别一上来就想做全。 建议第一阶段只做”变频器故障码查询”和”维修手册智能检索”两个功能,用1~2周跑通、收集反馈、优化知识库。想了解更多天车预测维护的整体框架,可以参考我们之前写的起重机预测性维护与PHM系统方案。,别一上来就想做全。 建议第一阶段只做”变频器故障码查询”和”维修手册智能检索”两个功能,用1~2周跑通、收集反馈、优化知识库。第二阶段再扩展到大车/小车故障诊断。第三阶段再加历史数据分析。分阶段上线,每个阶段都有可见效果,用户才愿意用。
结语
AI大模型在天车运维中不是花架子——当维修工在故障现场掏出手机拍张变频器报警照片、30秒后AI返回了故障原因和处理步骤的时候,这套系统的价值是不需要解释的。我们在两个车间试跑了三个月,维修工的平均故障定位时间从40分钟降到了15分钟,其中变频器类的常见故障基本能做到秒级响应。
整套系统需要的技术门槛不高:一台带显卡的工控机、一个Ollama、一个向量库、一套整理好的知识库。最花时间的不是装软件,而是把维修经验从老师傅脑子里搬到知识库里——但这恰恰是最值钱的部分。
Perguntas frequentes
问:天车AI运维助手需要多大的硬件投入?
答:本地部署一套完整的AI运维助手系统,硬件配置最低为工控机(i7/32GB/RTX4060 12GB),含软件费用总投入约3~8万。如果不需要本地推理(纯云端调用),一台普通工控机即可,投入1~2万。本地部署的好处是数据不出厂区、无延迟、不依赖外网。
问:大模型能处理天车的哪些故障类型?
答:覆盖三大类:电气故障(变频器报警代码、PLC通讯断线、传感器无信号——占60%)、机械故障(钢丝绳断丝、轴承异响、制动器拖刹——占25%)、综合故障(啃轨、定位偏差、能耗突增——占15%)。RAG知识库需要提前导入设备说明书、维修手册和历史故障记录,检索质量取决于知识库的完整度。
问:老师傅退休后知识怎么传承?
答:这正是AI运维助手最大的价值点。把老师傅的经验以问答对形式录入知识库——”制动器拖刹先查液压站油压还是先查摩擦片间隙?””变频器报OU过压故障在夏天高发,处理方法是什么”——每条问题配上详细的分步处理流程。建库时花1~2周把老员工的经验梳理进去,以后新人遇到同样问题直接问AI,不用再到处找人问。
